UCL-CENTRAL: Today I chased up the replication sft problem. I don't have any answer from my ggus ticket (#12970). William has mapped me to opssgm and I can sucessfully store files on their srm. When looking more in detail it seems that they are also openssl errors spitted by the server. They only appear when it is the "regular sft" that are running. If we use the polish portal we don't have the error. My bet it that the portal uses grid-proxy-init while the "regular sft" is using voms-proxy-init. It is probably because the vomses and vomsdir content is not completely correct. William is having a look at that.
ATLAS: I have contacted Alessandro to understand why some of the London sites are not in shown on their production portal. He explained me that they have to populate a list of sites to which they submit production jobs. I will make sure with Kondo that the atlas sw is there on all london sites.
CMS: The cms production is finished (50 millions events). CSA06 should start in the coming weeks to analyse the produced data that is fed back to CERN.
Woodcrest: Today we (me, Mona, Bill) physically installed all the machines we currently have (22 wn and 8 disk servers).
PPS: Barry is summarizing all the problems he went trough with the glite WMS. Hope to have this for the next operation meeting.
dCache: Having problems with the number of connection in close_wait state. This is a known issue to the dCache team. We don't know when it will be fixed. This causes replication failures ...
Transfer test: RALPPD-->QMUL transfer test worked. Average bandwidth 106Mbits/s and 1146/1500 files transferred. Clearly we should be able to do better since they have a 1Gb link which is not much loaded.
GridMon: Got an agreement with Mark to have the recepie to rebuild the GridMon box for Imperial and UCL. Kostas agreed to build it.
Brunel new cluster:Discusssions with Duncan on how to proceed with the new cluster.
Monday, September 25, 2006
Friday, September 22, 2006
Today is a horrible rainy day... I have been again busy with QMUL. For some weird reason lhcb has managed to schedule 2500 jobs there and none are running. I can even not see the jobs in the queue. I restarted the gatekeeper and I can see jobs being submitted by Ricardo. I still don't understand what was happening there. I have also tried to ressurect the ganglia of QMUL which is down. I could not power cycle it.
Transfer Tests: I have initiated a transfer of 100Gb from RALT2 to QMUL it seems to be fine for now.
Woodcrest: 20 new machines arrived today.
Transfer Tests: I have initiated a transfer of 100Gb from RALT2 to QMUL it seems to be fine for now.
Woodcrest: 20 new machines arrived today.
Thursday, September 21, 2006
Woodcrest: Asked ICT to reserve a set of UID/GID to avoid clashes between hep and ict.
Biomed Challenge: Asked Yannick to see if we can find another solution then inbound connectivity to the nodes for the flex licence.
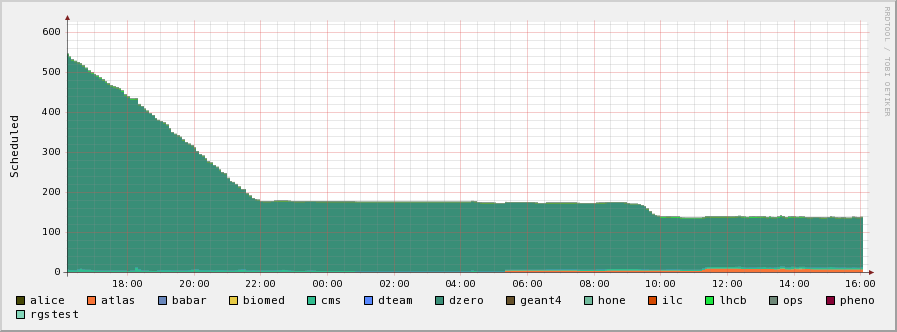
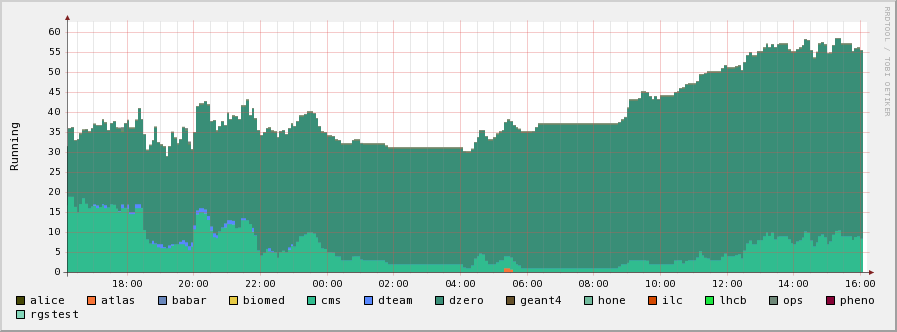
QMUL: try to understand what causes such a low number of running jobs while there is a lot of jobs queued. see attached plots.


Other Stuff:
Biomed Challenge: Asked Yannick to see if we can find another solution then inbound connectivity to the nodes for the flex licence.
QMUL: try to understand what causes such a low number of running jobs while there is a lot of jobs queued. see attached plots.
- DNS problem: very high load on the dns server. Process zombie when trying to kill it. All Grid services stuck. Could restart the dns and the situation seems to be stabilized.
- Maui conf: Reservation did not work if ops jobs where submitted on the long queue. This is because the reservation period was not set to infinity.
- dzero station sandbox full. All dzero sites affected. Frederic was waiting that QMUL is back to send jobs there for testing.
- I have investigated lesc to try to understand what causes such a low number of running jobs while there is a lot of jobs queued. see attached plots. On the left number of scheduled jobs and on the right running.
Other Stuff:
- SAM Monitoring: Asked all sites to check their status in SAM
- Asked to be mapped to ops to test UCL srm. No answer yet to the ticket #12970
- Installed new apel accounting rpms at UCL-HEP. Will see tomorrow if it has solved the problem.
Wednesday, September 20, 2006
QMUL:
NetMon: Trying to find a solution for the net monitoring box proposed by Robin. Admins wants to rebuild the machine. I am afraid this will take time to be resolved.
Woodcrest purchase: Today we have received 8 new boxes. The disks one. We have also debugged a problem with the pxe boot. It seems that some of our switches are not behaving correctly since the dhcp requests do not come back. Kostas is investigating further. For the CE we will build an old machine. We are ordering additional 1Gb memory for the CE that will go to ICT and HEP.
Dzero: Frederic has tested dzero at QMUL, it seems that the setup we have made for the TMP directory is ok. He is having concerns with the number of slots he is having at LESC.
- Certificates have not been upgraded, the tests are now critical and Giuseppe is on Holiday up to the 27/09. I will upgrade them since Giuseppe is on holiday. Have made a new rpm version 8 for the certs. Have a look at our wiki
- lhcb yaim settings have been changed to match their use of groups rather than roles. It seems ok and I am populating the LT2 yaim file with the corrected entries
NetMon: Trying to find a solution for the net monitoring box proposed by Robin. Admins wants to rebuild the machine. I am afraid this will take time to be resolved.
Woodcrest purchase: Today we have received 8 new boxes. The disks one. We have also debugged a problem with the pxe boot. It seems that some of our switches are not behaving correctly since the dhcp requests do not come back. Kostas is investigating further. For the CE we will build an old machine. We are ordering additional 1Gb memory for the CE that will go to ICT and HEP.
Dzero: Frederic has tested dzero at QMUL, it seems that the setup we have made for the TMP directory is ok. He is having concerns with the number of slots he is having at LESC.
Tuesday, September 19, 2006
QMUL: poolfs is down again. It says no space left on device. Restarting poolfs does not help. I have decided to reboot the storage element. The reason there was a poolfs problem is that the / was full. I have setup the logrotate for the logs to be compressed which is not the case by default in the logrotate file created by yaim. The se01 is back online.
All Hands 2006: Prepared an small talk "Towards Sustainability" to initiate discussions.
UCL-CENTRAL: still having problems with replication for the ops vo. Wiliam observed that if he runs the test using the submission tool it does not give a replication error. Submitted a ticket (#12970) to understand the differences.
IC-HEP: Viglen as delivered the racks and two machines. We are preparing to install them.
RHUL: Going down for the week-end.
All Hands 2006: Prepared an small talk "Towards Sustainability" to initiate discussions.
UCL-CENTRAL: still having problems with replication for the ops vo. Wiliam observed that if he runs the test using the submission tool it does not give a replication error. Submitted a ticket (#12970) to understand the differences.
IC-HEP: Viglen as delivered the racks and two machines. We are preparing to install them.
RHUL: Going down for the week-end.
Monday, September 18, 2006
SC4 CMS: Last friday Brunel was validated for CMS production. It is now running full with cms jobs. We had to play with the dpm permissions to make this work and now doing the same at RHUL. I am trying to keep the London SC4 activity page updated. See below a plot taken on the 18/09/2006 showing the Brunel activity. QMUL:
QMUL:

 Frederic is having problems with dzero jobs. A lot of jobs are scheduled but they seem to dissapear. See the two plots below. I suspect that some of the jobs have a very short time because of a stager error and they are not seen as running since they last for less than five minutes. We will check in the root file to see what wall clock time distribution the job have.
Frederic is having problems with dzero jobs. A lot of jobs are scheduled but they seem to dissapear. See the two plots below. I suspect that some of the jobs have a very short time because of a stager error and they are not seen as running since they last for less than five minutes. We will check in the root file to see what wall clock time distribution the job have.
IC-HEP: Our rb is creating a lot of proxy renewal and filling up the disk., Mona is investigating.
We have received two woodcrest from Viglen and I need to check with the order.
UCL-CENTRAL: Alice left thanks for her work !
We have problems with the ops vo, the replication does not work. William saw that it is due to the default se that is not set correctly. Probably a bug in yaim. It should be fixed now.
 QMUL:
QMUL:- poolfs died, the index is not reachable. It seems that autofs is not behaving correctly. I did not dare to restart the machine remotely and I made a hard mount to the index under /tmnt/poolfs. dpm is back.
- Prepared qmul for cms sc4 . Waiting for the cmssw to be installed and will have to make the dpm hack.
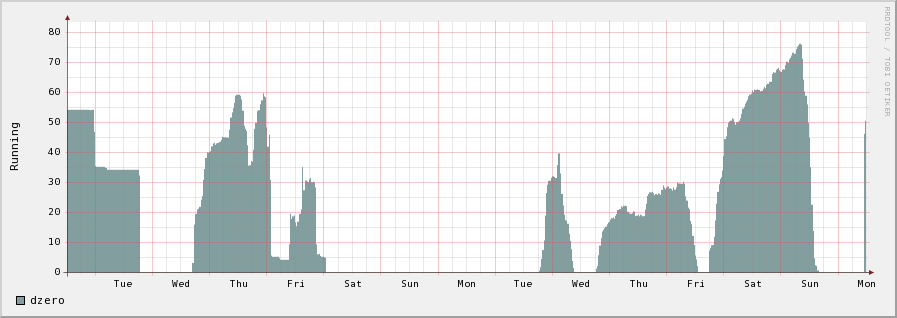
 Frederic is having problems with dzero jobs. A lot of jobs are scheduled but they seem to dissapear. See the two plots below. I suspect that some of the jobs have a very short time because of a stager error and they are not seen as running since they last for less than five minutes. We will check in the root file to see what wall clock time distribution the job have.
Frederic is having problems with dzero jobs. A lot of jobs are scheduled but they seem to dissapear. See the two plots below. I suspect that some of the jobs have a very short time because of a stager error and they are not seen as running since they last for less than five minutes. We will check in the root file to see what wall clock time distribution the job have.IC-HEP: Our rb is creating a lot of proxy renewal and filling up the disk., Mona is investigating.
We have received two woodcrest from Viglen and I need to check with the order.
UCL-CENTRAL: Alice left thanks for her work !
We have problems with the ops vo, the replication does not work. William saw that it is due to the default se that is not set correctly. Probably a bug in yaim. It should be fixed now.
Monday, September 11, 2006
Activity restarted after Holiday
I have tried to recover from my emails.
- I have started to gather the slides/data for the rtm talk of friday Service Challenge Technical Meeting .
- dCache head node was down due to a full /var. Mona cleaned the directory and started to look at the nagios dCache scripts
- Duncan is off ill and I will have a look at the RHUL sft failure
- Started discussing with Matt Harvey (ICT) about the pbspro they are using. We will have to adapt the job manager to that version
- Gave contact details to Mark Leese for the Net box to have one at Imperial and asked William if he is happy with having such a box at UCL-CENTRAL
- Giuseppe wanted help to create 100*1Gb files in his dpm. suggested him to use rfcp from one of his cn nodes.
- Jamie told to hold since Alice was performing UCL-CENTRAL tests.
- Followed the castor/d-cache phone conf that was held at RAL.
Subscribe to:
Posts (Atom)